Kafka Reblance问题排查
背景
当我们的服务用Golang重构完成后,在发布Kafka Consumer服务过程中遇到一个奇怪的问题就是发布后的一个小时内出现了大量的数据积压,一小时后恢复正常消费。
经过排查发现,服务在这一小时以内频繁进行Reblance,需要排查原因。
Reblance的触发条件
- 有新的consumer加入
- 有consumer下线
- topic内partition数量变更
- consumer client拉取消息后长时间没消费(max.poll.interval.ms,这个时间这个参数,这个是java client里的参数,golang sarama没有这个参数,我们的rebalance不是这个引起的)
原因1有这些场景可以引发:服务发布(新服务加入消费者组),consumer被踢下线后重新加入
原因2有这些场景可以引发:服务发布(发布完后旧的服务被删除),心跳连接失败持续一段时间后被Kafka踢下线
原因3需要平台SRE操作,一般情况下不会触发
原因4是java client的参数,golang的sarama组件未使用这个参数,所以我们服务的rebalance不是这个原因导致的
Reblance的执行逻辑
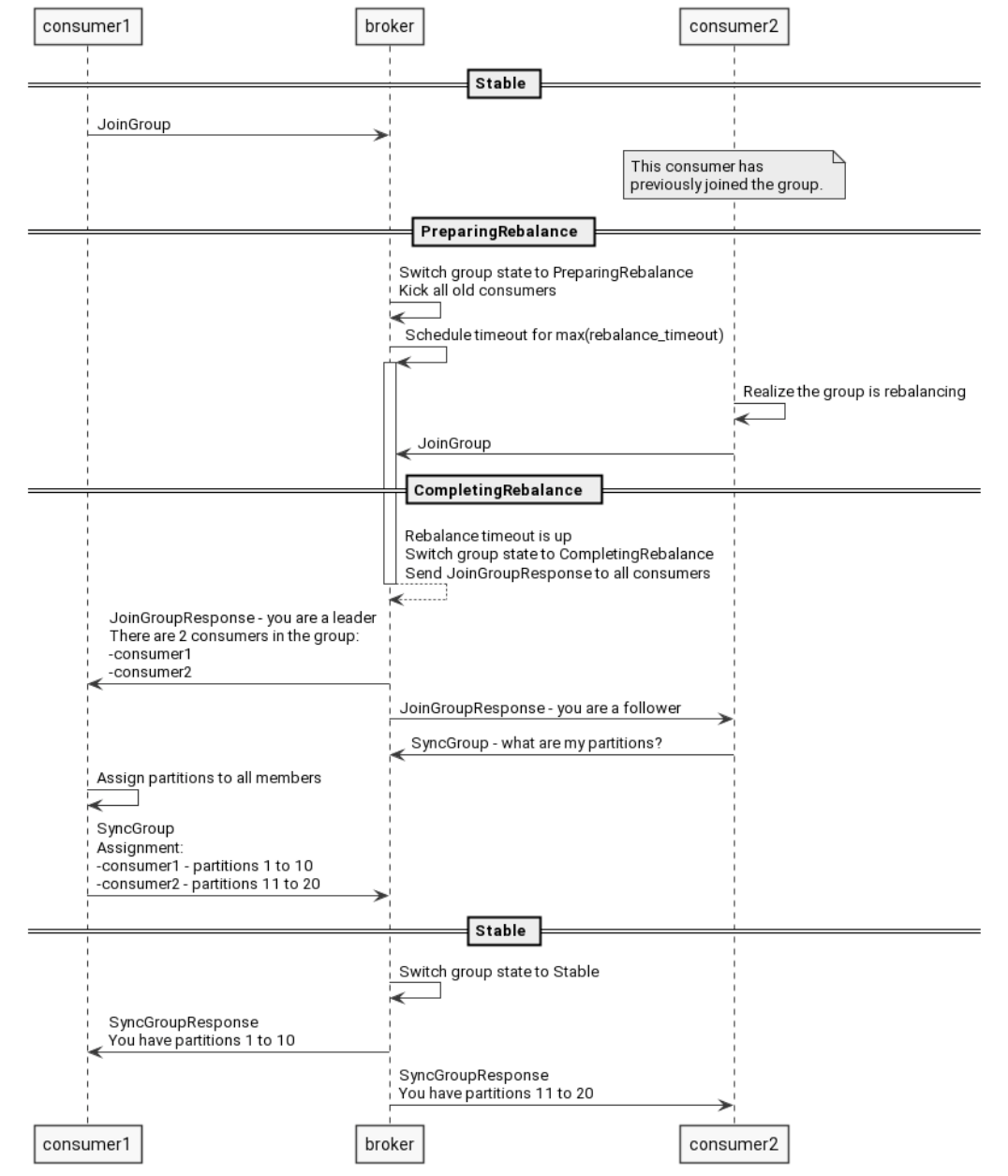
Consumer设置的Config.Consumer.Group.Rebalance.Timeout参数会上传给Coordinator, Coordinator在触发Reblance的时候根据这个设置进行等待,如果未在这个时间内重新加入group,则Reblance流程不会继续等待,会按此时已加入的Consumer进行分配。(如果多个Consumer的设置不一致,会自动使用最小的timeout值)
根因分析
结合Reblance的逻辑以及官方文档中提到的一个可能导致无限Reblance的一个错误用法,服务出现长时间Reblance问题的根因如下:
服务发布的时候,有新的消费服务加入consumer group,触发上述条件1,引发第一次rebalance
在rebalance期间(config.Consumer.Group.Rebalance.Timeout 默认值为 60s),消费者可以处理已经拉取的消息,Kafka topic中新产生的消息不会被消费者拉取,rebalance期间topic中新的消息会被积压
等rebalance完成后,在这一轮rebalance过程中完成rebalance的消费者开始批量拉取消息,进行消费,由于上述步骤2的rebalance过程中,有消息积压,这次拉取的消息会比较多
服务部署的时候,容器是逐步替换并下线的(如果同时发布多个region,整个容器替换的过程时间会更久),就会导致在上述步骤3后还有新的consumer加入consumer group,此时又会触发rebalance的原因1,发起新的一轮rebalance
新一轮rebalance的时候,步骤3中的部分consumer因为拉取到了之前积压的消息,消息比较多,未消费完,就不能加入当前轮次的rebalance,同样的,本轮rebalance过程中,新的Kafka消息也不会被消费者拉取,会被积压
步骤5中rebalance完成后,完成rebalance的消费者拉取消息进行消费
步骤5中,有部分consumer因为消息积压,未能及时处理完消息,没有加入rebalance,等这些consumer处理完拉取的消息,会重新加入consumer group,发起新的一轮rebalance,此时又有一部分consumer因为在消费存量的消息,没能加入本轮的rebalance
重复上述步骤的5~7,消费者consumer group就会持续rebalance,直到topic中存量积压的消息消费完,在某一轮rebalance过程中,全部consumer加入rebalance后,才会停止rebalance

解决方案
消费者在消费每条Kafka消息前,判断是否发生rebalance,如果发生了rebalance,就直接返回,不再消费消息,快速加入当前轮次的rebalance,尽快稳定下来。避免因为未消费完拉取的消息,没有加入rebalance而导致不断被Kafka集群下线又不断加入的过程
1 | |
参考文档
How to avoid the infinite rebalance issue on Sarama consumer usage