布隆过滤器
一、布隆过滤器简介
布隆过滤器,英文叫BloomFilter,可以说是一个二进制向量和一系列随机映射函数实现。 可以用于检索一个元素是否在一个集合中。
下图是一个例子,来看一下布隆过滤器的工作流程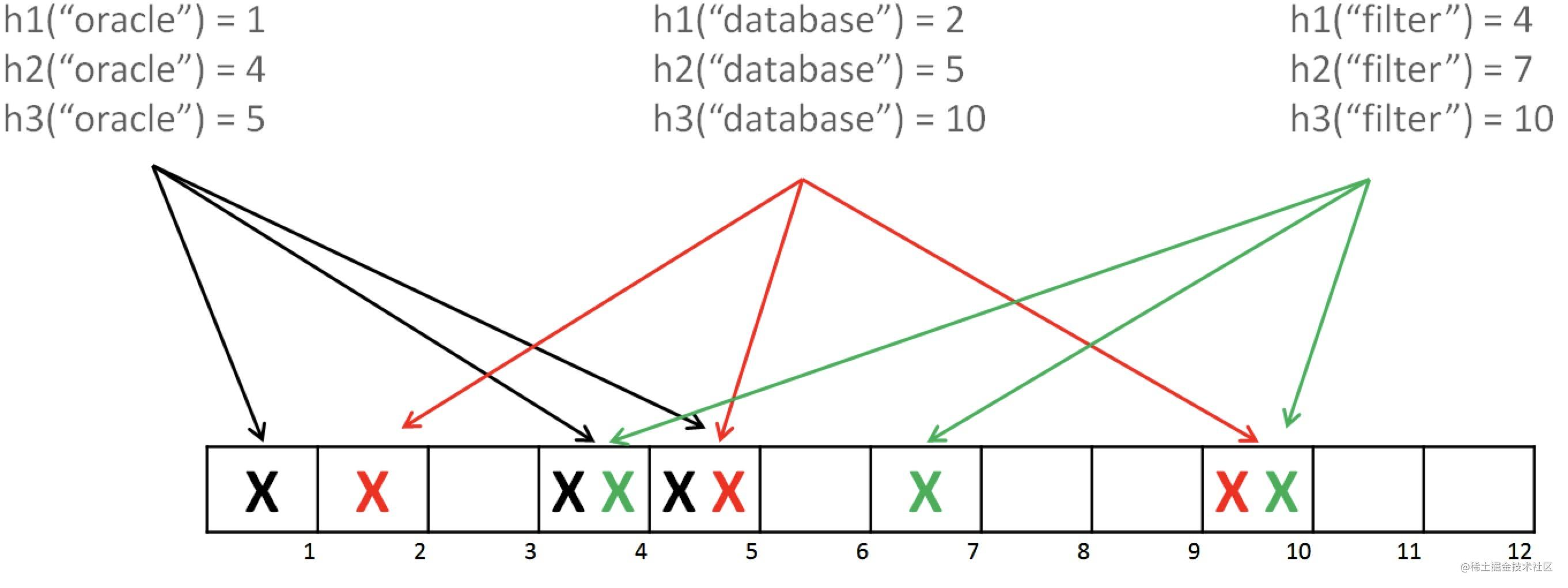
有三个hash函数和一个位数组,例如单词oracle经过三个hash函数,得到第1、4、5位为1,在初始化时将数组的1、4、5位置为1. 后续如果我们需要判断oracle是否在此位数组中,则通过hash函数判断位数组的1、4、5位是否均为1,如果均为1,则判断oracle在此位数组中。这就是布隆过滤器判断元素是否在集合中的原理。
二、布隆过滤器存在的问题
了解了原理之后,也很容易发现它存在的两个问题: 误判 & 不可删除
1. 误判
还是上面的例子,如果bloom经过三个hash算法,需要判断 1、5、10位是否为1,恰好因为位数组中添加oracle和database导致1、5、10位为1,则布隆过滤器会判断bloom在集合中,导致误判。
因此,高效插入和查询的代价就是,它是一个基于概率的数据结构,只能告诉我们一个元素绝对不在集合内,对于存在集合内有一定的误判率。
但是布隆过滤器的空间效率和查询时间都远远高于一般的算法,使得这个缺点在某些应用场景中是可以接受的
2. 不可删除
布隆过滤器判断一个元素存在就是判断对应位置是否为 1 来确定的,但是如果要删除掉一个元素是不能直接把 1 改成 0 的,因为这个位置可能存在其他元素,直接删除会对其他元素的判定结果产生影响。
三、应用场景
- 网页黑名单过滤:由于互联网上存在大量的恶意网站和垃圾网站,为了保护用户的隐私和安全,很多网站都会采用布隆过滤器来过滤黑名单中的网站。
- 垃圾邮件过滤:在邮件服务器中,需要对接收到的邮件进行分类,将垃圾邮件过滤掉,保证用户只接收到有用的邮件。布隆过滤器可以对邮件进行快速过滤,提高过滤的效率。
- 缓存过滤:在缓存中,需要快速判断某个键值对是否存在。如果缓存中的键值对非常多,使用线性搜索的方式会非常耗时。这时可以使用布隆过滤器对键进行过滤,减少无用的搜索。
- URL去重:爬虫在爬取网页时需要去重,防止重复下载同一个页面。布隆过滤器可以快速判断URL是否已经被爬取过。
四、实践中遇到的问题
1.如何降低误判率(fpp)?
我们可以提高数组长度以及 hash 计算次数来降低误报率,但是相应的 CPU、内存的消耗也会相应的提高;这需要我们根据自己的业务需要去权衡选择。
1.1 布隆过滤器应该设计为多大?
假设在布隆过滤器里面有 k 个哈希函数,m 个比特位(也就是位数组长度),以及 n 个已插入元素,错误率会近似于 (1-ekn/m)k,所以你只需要先确定可能插入的数据集的容量大小 n,然后再调整 k 和 m 来为你的应用配置过滤器。
1.2 布隆过滤器应该使用多少个哈希函数?
对于给定的 m(比特位个数)和 n(集合元素个数),最优的 k(哈希函数个数)值为: (m/n)ln(2)
2.如何支持删除
如果要支持删除,最简单的做法就是加一个计数器,就是说位数组的每个位如果不存在就是 0,存在几个元素就存具体的数字,而不仅仅只是存 1。
那么这就有一个问题,本来存 1 就是一位就可以满足了,但是如果要存具体的数字比如说 2,那就需要 2 位了,所以带有计数器的布隆过滤器会占用更大的空间。